For some reasons, the code that checks the output of the shader messes with the results (even if it’s not between the start/end timing marks!). In my testing, I alternate between a small and a big duration:
If I comment out the code that checks the array, I don’t experience this problem:
Note that it seems the accuracy of performance.now is 0.1ms, so timing things that are < 1ms won’t be very precise.
Also, you sometimes get a measure or two that can be quite bigger than the other measures, and it will bias the average. It’s probably due to the browser and/or what happens at that time on the computer. For a better average calculation, you should remove the X biggest / smallest values to compute the final average.
Note that the PR is now merged, and is available on the Playground.
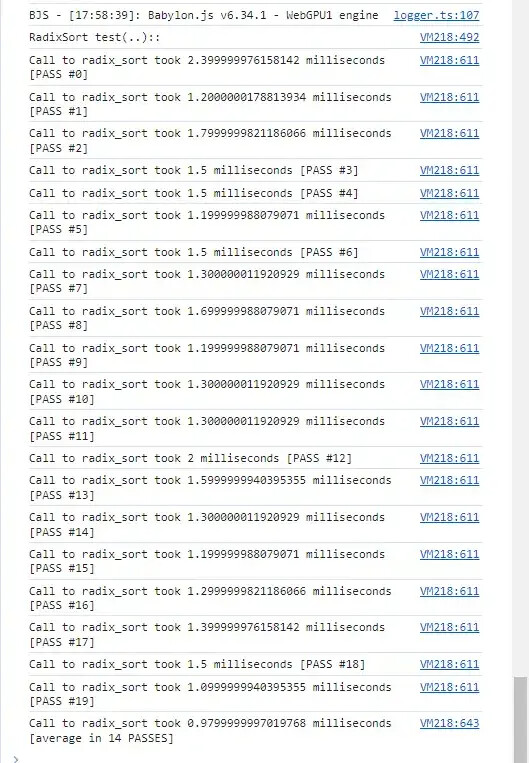
I tested it on my computer (I implemented the average calculation as explained above and commented out the code that checks the array):
with native webgpu API no performance drops (4/4 passes) I still think that you need to calculate the average, otherwise it’s cheating
on PG (webgpu#6E7FJ1#5) the difference seems to be 2.5 ms vs 1.3 ms (with 3/4 passes), but when running locally (on my PC) there is suspiciously no difference (1.7-2 ms, with 4/4 passes)
with “promises” (fastMode=true, webgpu#4EI0PY#13) prefetch code results of radix sort is not correct (see log “count_unmatch: 2097151”)
because you comment on the result log, but the problem remains
P.S.:
if you remove this code below then the results are ok (log “count_unmatch: 0”),
but if left, the results do not match the presorted references (see log “count_unmatch: 2097151”)
so your promises cause an error as a result
const promises = [];
for (let i = 0; i < bits; i++) {
let j = i % 2;
{
{
promises.push(pipeline_radix_scan1_buf[j].dispatchWhenReady(0, 0, 0).then(() => pipeline_radix_scan1_buf[j].fastMode = true));
}
for (let k = 1; k < buffers_scan1.length; k++) {
promises.push(pipeline_radix_scan2_buf[k - 1].dispatchWhenReady(0, 0, 0).then(() => pipeline_radix_scan2_buf[k - 1].fastMode = true));
}
for (let k = (buffers_scan1.length - 1) - 1; k >= 0; k--) {
promises.push(pipeline_radix_scan3_buf[k].dispatchWhenReady(0, 0, 0).then(() => pipeline_radix_scan3_buf[k].fastMode = true));
}
}
{
promises.push(pipeline_radix_scatter_buf[j].dispatchWhenReady(0, 0, 0).then(() => pipeline_radix_scatter_buf[j].fastMode = true));
}
}
await Promise.all(promises);
I calculate it! I simply remove the extreme values, because they just happen (for some reason beyond our control (GC?) - or at least I don’t see what we can do about it).
For eg:
Clearly, the average time should be around 0.5, but due to the high value of 5.1, the average will be 0.98.
Do you have the PR merged in your local Babylon sources?
My bad, I forgot the Update_PipelineRadixScan1_buf(j, i); call in the pre-fetch loop:
Note: I’m not sure what you mean when you say “3/4 passes” or “4/4 passes”. What I meant on my side with “3/4 passes” was that I ran the PG 3 or 4 times (in fact, I think it was more 5 or 6) and I did an average of the average displayed at the end of the test.
this is cheating because FPS is determined by the average frame time per second, not just frames outside of extreme values
sad
what I need to do for this ?
in your this link to PG states that :
const fmode = false;
this is not fast promises prefetch mode as I think, and if I set it to “true” than radix sort result is not correct “(see log “count_unmatch: 2097151”)”
this does not affect the result in any way
I mean that code used your timer wthout extrime values
I mean that code used my timer with all values of duration
P.S.:
and so PG time result of benchmark with promises prefetch with “fmode = true;” is fast (0.8 ms average, the same as in the native webgpu API), but the results are incorrect (do not pass the check, see log “count_unmatch: 2097151”))
You will be able to call engine.flushFramebuffer() to submit the current command buffers and reset the ubo GPU buffers, which will fix the problem.
See:
I call engine.flushFramebuffer() at the same point where the native code submits the command buffers.
Note that you are still able to use native code in Babylon if you wish, as you can access the device through engine._device (in the same way we have engine._gl for people that want to issue direct WebGL commands).
The first one is faster than the second one, but the flushFramebuffer call should also be done in the first case, else it is not comparable: currently, device.queue.submit(...) is never done during the tests in the first PG, it is done only after tests are finished because it is done in the engine.endFrame method.
I now start a test each frame and not run a loop of X tests during the same frame. I think there are some strange interactions with the browser when we do all the tests in a single requestAnimationFrame…
However, there’s a way to make it work without calling flushFramebuffer: create as many compute shaders as necessary to avoid having to update the uniform buffers during the loop.
It means you must create “bits” (=30) compute shaders instead of 2 for pipeline_radix_scan1_buf. It’s not really a problem, and on my computer the “promise” version is on-par with / slightly faster than the native one (though, if you would make the same changes in the native version, you would be faster too)!
You don’t need the rollback above to have it work in the current Playground:
I already set up the timers and here we have, it builds from 25 to 250 thousand triangles in 1.3 ms on average (excluding heavy initialization operations, like the initial creation of buffers)
even if we count the initial creation of temporary buffers (except for creating and copying the model’s triangle array to VRAM), then on average 2-3 ms
(but it is clear that there is no need to recreate the buffers for each frame)
P.S.2:
and yes, if someone wants to dig into it, then keep in mind that all operations like await device.queue.onSubmittedWorkDone() needs to be removed (I don’t remember the details now, but it’s a really slow thing - which is not necessary), everything works without it (and it’s orders of magnitude faster)
and if anyone is interested, out of these 1.3 ms, radix-sort takes a whole 1 ms there is an assumption that it is possible to even speed it up (for example, by caching operations (?) or by abandoning atomics) - about 2 times (or more ?), but it is clear that this is already excessive (at least for now)