When creating GreasedLineMesh, it’s observed that the creation is very slow when having ~10k points, example below, see console for creation time, which takes 5310ms on my laptop:
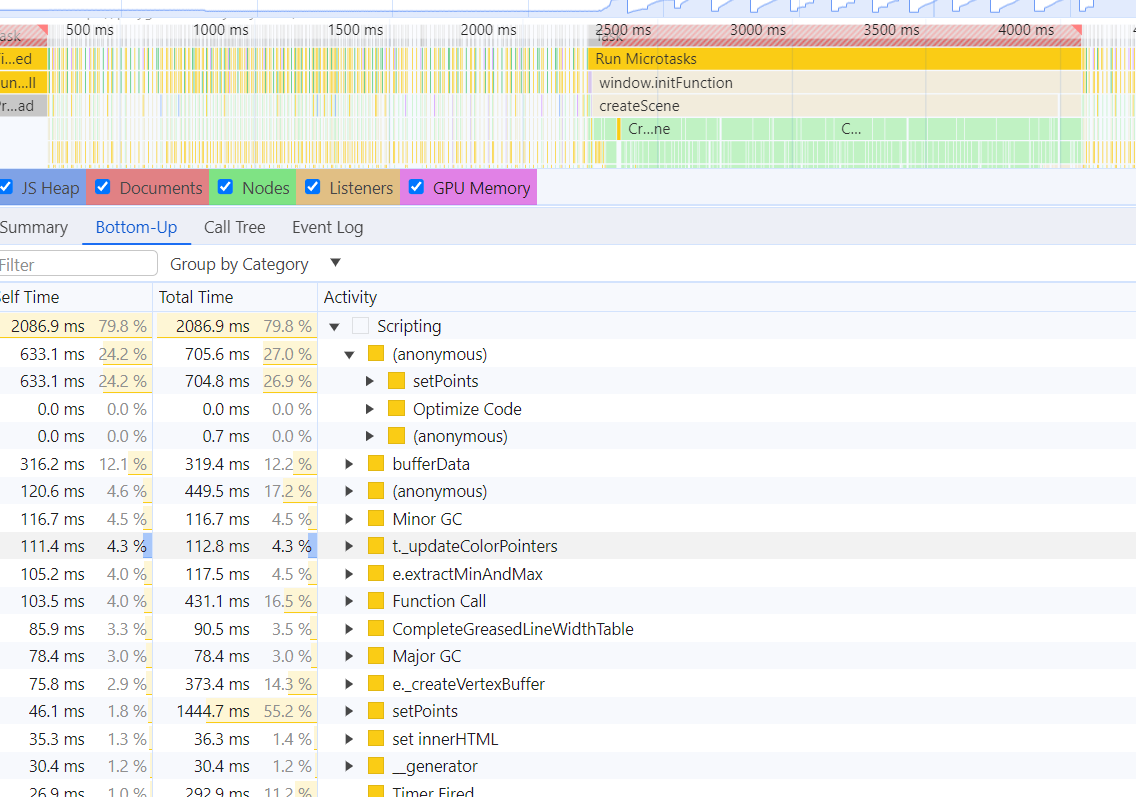
After profiling with chrome devtools, we found that the performance bottleneck is function GreasedLineMesh._setPoints
And the GreasedLineTools.GetLineLength code is here:
We analyzed into the algorithm, and found that the time complexity of it is O(n^2), where n is the number of points.
In line 101 of GreasedLineMesh._setPoints code above, p.slice(0, jj + 3); creates a copy of points array from the beginning to current index, and GetLineLength is executed over this, so the length of previously computed points are evaluated again for each point following.
To optimize this, a fairly simple way is to cache the length of previously computed points, after this, the p.slice(0, jj + 3); call can be removed so there should be less memory allocated after this optimization.
The optimized code is here, which uses ~60ms for the first run, and ~30ms for next run:
You too buddy!
And of course @kzhsw to you as well!
The main bottleneck in GreasedLine is setting/updating the points and preparing the underlying GPU buffers. I was already thinking about optimizing but honestly my first thoughts were to prepare the buffers by a compute shader and I didn’t think about to start looking at first at the javascript code.
Very well done @kzhsw ! I tested your PG with 50.000 points: const points = BABYLON.GreasedLineTools.GetCircleLinePoints(100, 50000)
The algorithm seems mainly memory lookup and copy operations, to futher optimize it, consider precompute length of arrays, instance property this._vertexPositions, this._indices, and local vars counters, positions, and allocate them as Float32Array, this should reduce allocations by reducing array.push, which can make memory reallocated as array grow.
Preallocate array optimization (~30ms → ~20ms):
Making positions and indices zero copy:
Making uvs preallocated, and eliminate side, counters, and some branches:
Making _previousAndSide and _nextAndCounters preallocated, ~12ms when after warmup:
Also, since there are not too much calculations here, the algorithm might not benefit too much from compute shaders, as the overhead of copying memory to gpu and the latency of invoking compute shader would also introduced by compute shaders.
BTW, if I understand correctly, this code pushes the same point to positions twice, if this could be indexed, there might be some performance gains.
There is also a few things left for futher optimization of GreasedLineMesh:
in _setPoints, building previous and next array takes considerable time if run for multiple times, it could benefit if we can eliminate it like side and counters, but doing this would split the loop to 3 parts.
_updateColorPointers and CompleteGreasedLineWidthTable takes considerable amount of time after optimization of the pr, which can also benefit from the preallocated typedarrays optimization.
WoW. I think you’re about to become @roland best friend…and by extension, mine as well
I’m so eager to see what your joined forces will be able to accomplish from all this
Yes! I’m glad someone makes the optimalizations of GreasedLine. I have it on table for a long time already but didn’t have the opportunity to start making the stuff…
@kzhsw can you please make the changes in greasedLineRibbonMesh.ts file where it’s needed as well? Thanks a lot!
I can hear you on that. For me, optimization is always the last thing in the tickets and somehow, it tends to always slip through Probably because I’m no real dev… as long as it works and looks good…fine by me
Yes YOU ARE! However while in business we have to make tough decisions and sometimes we have to make things just good enough.
Fortunatelly the open source has a big advantage: there are plenty of coders who pushes (or push??? damn I have to practice English) your good enough code to a masterpiece! @kzhsw
Since gc takes a large part of time, this could benefit from using preallocated vector when doing calucations, or inlining the calucations maybe.
Perallocated typedarrays could work, but the algorithm here is far too complex here than the one of GreasedLineMesh, so this could be some long-term thing.
Unlike the algorithm of GreasedLineMesh, this algorithm makes a lot of compute, and not using trigonometric functions at runtime, so it might also benefit from simd, but this could be out of the scope of babylon.js.

 ms
ms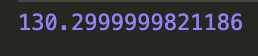 ms
ms