Calls readTexturePixels multiple times every 3 seconds:
Old version:
New version:
Async test:
#ASX6HW#5
Functional test - read texture pixels and create a texture from the pixel data
Calls readTexturePixels multiple times every 3 seconds:
Old version:
New version:
Async test:
#ASX6HW#5
Functional test - read texture pixels and create a texture from the pixel data
As I mentioned in the PR, it would be great to have a perf tests ![]() to be sure we are not impacting existing systems.
to be sure we are not impacting existing systems.
Hi! Sorry for the delay! What kind of perf tests? What do you want to measure?
Would be great to be able to compare overall CPU GPU Memory usage and being sure for instance that to read 1*1 pixel the async part is not more overhead than a sync read. Also this should help appreciate the gain on larger textures.
Basically a bit of different cases from the lightest to the heaviest in order to compare sync vs async ?
I see.
So there might be cases (small textures) where the sync version will run faster than the async one and we wanna switch to async only when it pays off.
Right?
maybe, but first and foremost we need to know the difference so we can make an informed decision
Not sure ![]() It is exactly why it would be great to have the data and a way to get them.
It is exactly why it would be great to have the data and a way to get them.
Hi Roland!
I found your commit in the history, but the actual file in the master did not change. Do you still plan to fix the async read pixel?
I had to postpone this PR due to lack of time but now it’s really time to finish the PR.
We need to do some performance tests. There is some overhead switching the GPU to async mode so when reading smaller arras of pixels it could be quicker to use synchronous reading. I just came home from vacation so I can write the tests and finish the PR. Stay tuned.
Guys, so I finally got back to this PR. You proposed to make a sync gpu call if it performs better than the async call. Shouldn’t we let the developer decide which version he wants to use?
I am not sure whether it’s a good approach to fool anyone by calling the function async and perform a sync call when some conditions are met. If one wants a real async gpu call, let’s take the developer’s decision into account.
We could add some recommendations to the docs though.
In that case we should leave it unchanged by default and maybe let the user change it if they want to?
Currently the async version only wraps a sync gpu call in a promise.
I know but it works:) until we know if the new version is faster and as stable we should not touch it
I’m not that experienced to argue with you master but I allowed myself to ask ChatGPT for another opinion:
Comparison of sync gpu cal wrapped in a promise vs async gpu call:
Performance: Using a true async GPU read will generally yield better performance because it avoids stalling the pipeline. Wrapping a sync operation in a promise only avoids blocking the JavaScript thread but does not eliminate GPU stalls.
Code Simplicity: Wrapping a sync call in a promise allows you to use async/await for cleaner code, but it doesn’t offer performance improvements over the sync operation. True async reads require more complex logic for managing state, but provide better performance.
Latency: With a promise-wrapped sync call, you get immediate data with potential stalling. With an async GPU read, you may experience a delay in retrieving the data, but your overall app performance will be smoother.
In short, if performance is your concern, true asynchronous GPU reads (when supported) will always outperform wrapping a sync
gl.readPixelsin aPromise. However, if true async GPU reads are not available in your context, a promise can at least help maintain a clean, non-blocking API for your code logic.
However what bothers me is that we are faking the async stuff by the promise wrapper regardless of which performs better and we are forcing the developer to use the sync gpu call.
However as I already prepared the code for the async version I could make a few tests even though the result may vary from GPU to GPU, driver to driver.
The main concern to be honest is not perf (you are right this should be similar) but more on making sure GC is not impacted.
We can simply turn on the real async version and revert later if we find an unexpected issue
4K texture read executed 10x
16K texture read executed 10x
16K texture read executed 10x - no data conversion
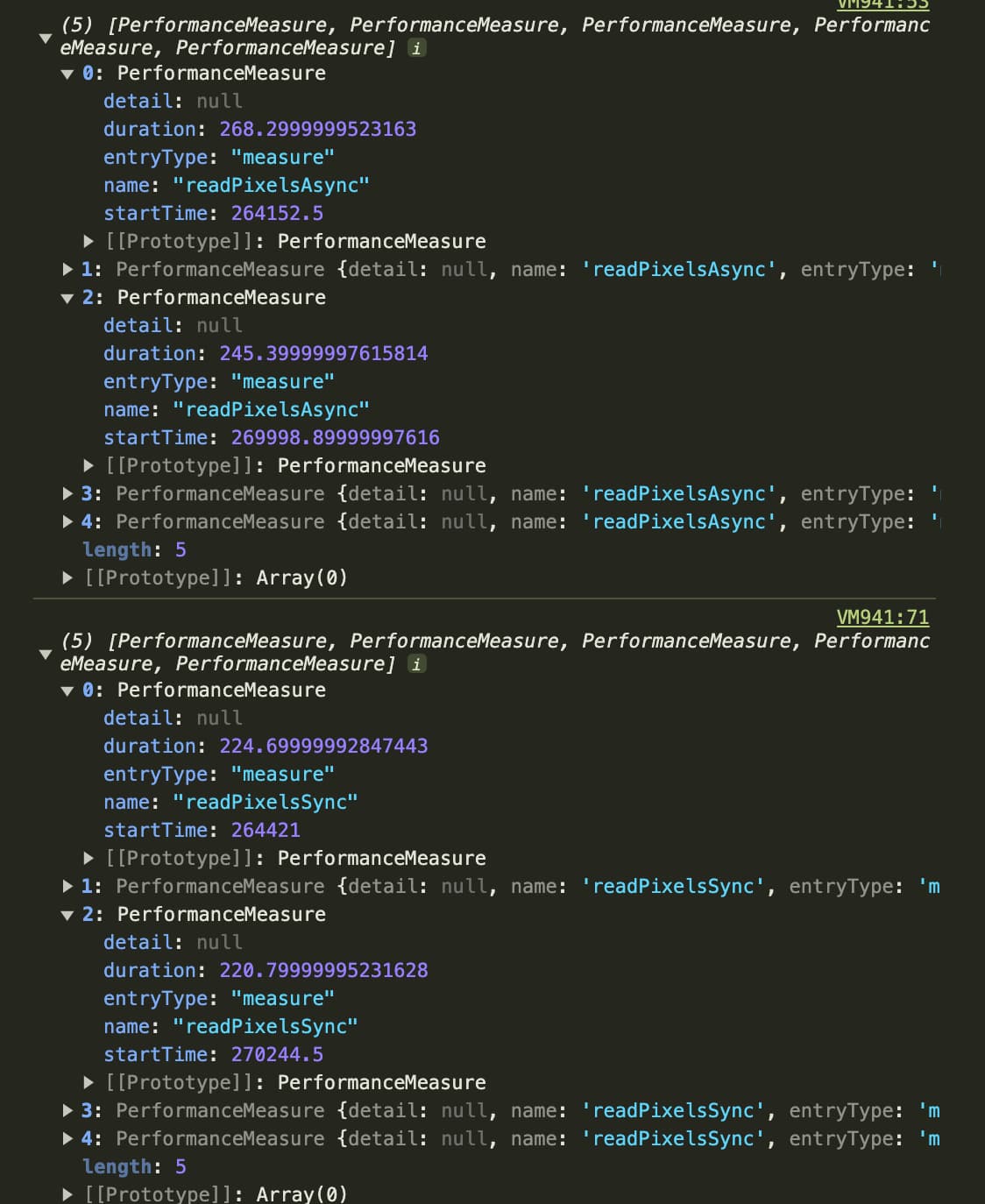
I’ve experimented with double buffered PBOs too and ran a bunch of other tests with various code I found in articles dealing with pixel reading from the GPU/various settings (perf measures not presented here).
My conclusion is that true async read is much more performat w/o data conversion in all cases. With data conversion the sync read is very slightly performant in most scenarios. As we almost always require data conversion (do we?) it seems we don’t need to touch the current implementation and the Promise wrapper is a good solution. EDIT: I’m doing some more experiments and starting to be unsure about this paragraph.
Contrary to all the test results I’m not sure whether I could measure the async version correctly:
@Deltakosh I’m still convinced we should give the user the ability to choose from sync or real async pixel reads.
Beware: even if you do a billion more experiments, that will be N=1 only!
Do i understand correctly that you tested time elapsed by readpixel itself?
As I understand, we need to test FPS in two 3D tests with expansive 3D rendering plus on top of that readpixels (synced and asynced) to test real case scenarios.
The problem we want to fix here is that synced readpixels blocks the rendering pipeline and reduce FPS, not the readpixels’ speed.
For example, when you want to select in a game a unit with the mouse, you do not need to have that data in the same frame your mouse over the unit. It can be 2-5 frames later and will still be okay, but you want to have as much FPS in your game as possible.
I can confirm that a scene with a rotating cube and 10 consecutive Promise wrapped gpu sync readpixels caused a stutter in the rotation but the real gpu async read didn’t.